
原生数据
实验室已有采集到的原生数据:原生题目、学生笔迹、批改分数等,实验室目前正在基于原生数据进行数据分析、信息挖掘等研究内容。
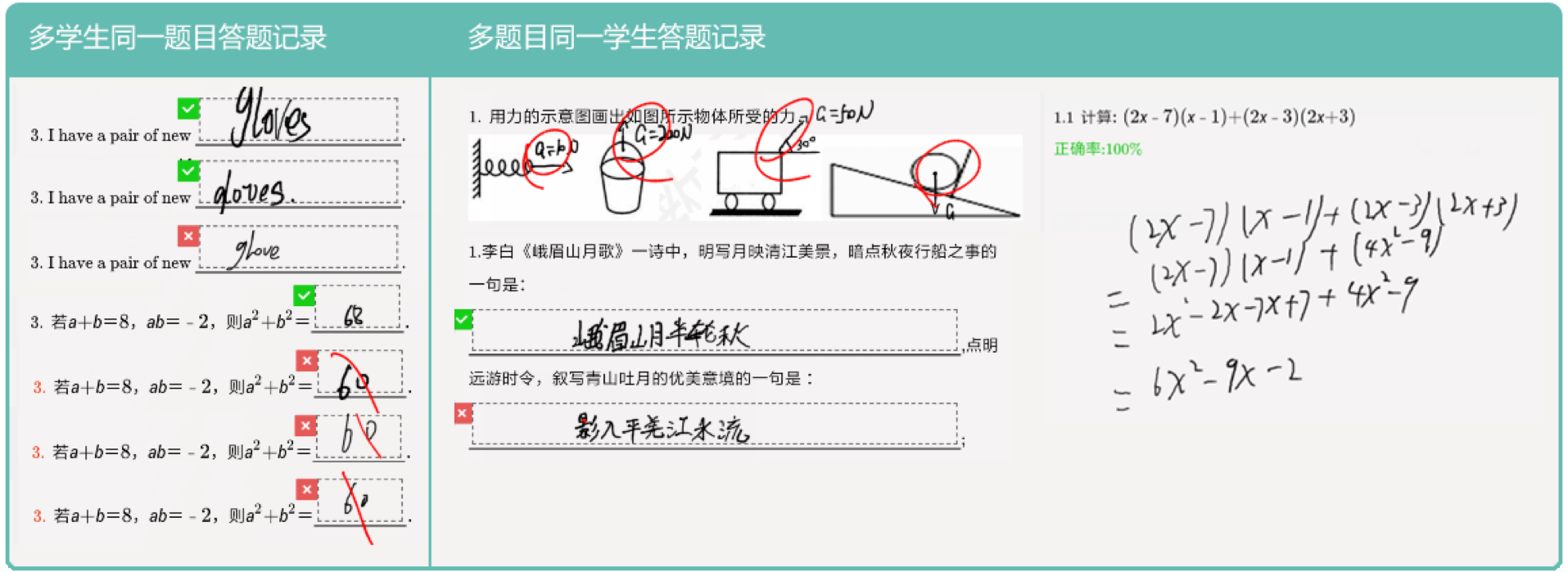
研究方向
知识追踪
知识追踪通过学生过往做题情况来刻画其相应知识点掌握程度,进而对学生未来的做题表现进行预测。研究室对知识追踪任务进行了深入研究,已有初步研究成果。研究室提出利用对抗训练来增强模型的泛化能力,有效提升了追踪效果,相应成果已被多媒体领域国际顶级会议ACM MM 2021收录(Oral)。
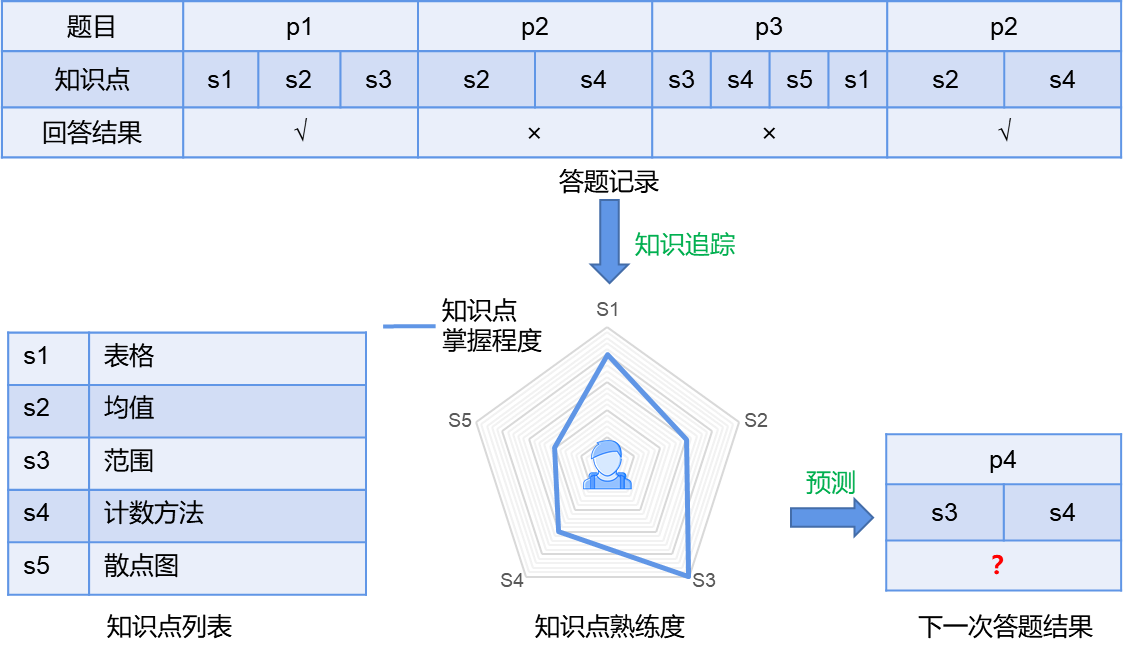 知识追踪图示
知识追踪图示
自动批改
当前原生教育领域的作业、考试均以人工批改为主,人工批改耗时耗力,效率低下。实验室利用收集到的数据进行学生笔迹识别、题目自动批改等相关研究。由于手写笔迹具有高噪音、多风格、不规整等特性,直接进行识别的正确率无法到达批改场景的应用门槛。本方向致力于研究智能化批改技术,解放老师双手。
 自动批改图示
自动批改图示
图文纠错
目前教育领域的题目资源分散,题目的数字化存储是建立题库、资源共享的前提基础。采用文本扫描识别技术(OCR)可以大大减少题目数字化的负担,但在实际应用中,OCR系统仍需要辅以人工纠错才能得到确切的文本。本课题将扫描图片和题目文本映射到同一编码空间,对照二者差异生成纠错提示框,探索题目数字化的全自动方法。
 图文纠错图示 |
 题目推荐图示 |
|---|
题目推荐
目前主流题目推荐方式是根据题目的客观相似度,根据最长匹配子串、关键词、考点标签等计算得出。逻辑上,题目的主观相似度——题目难度也是题目推荐中不可缺少的,而计算主观相似度所需要的学生答题记录较难采集,限制了主观相似度的计算与应用。本项目旨在根据题目特征和学生特征协同过滤相似题目,对任一学生及其在历史题目中的答题效果推荐有针对性的题目集合。
学生建模
基于学生多维学情大数据为学生建立学情画像,通过横向和纵向等多维对比进行特征分析,对学生的学习能力和习惯进行分类建模,实时预测学生学习状态。
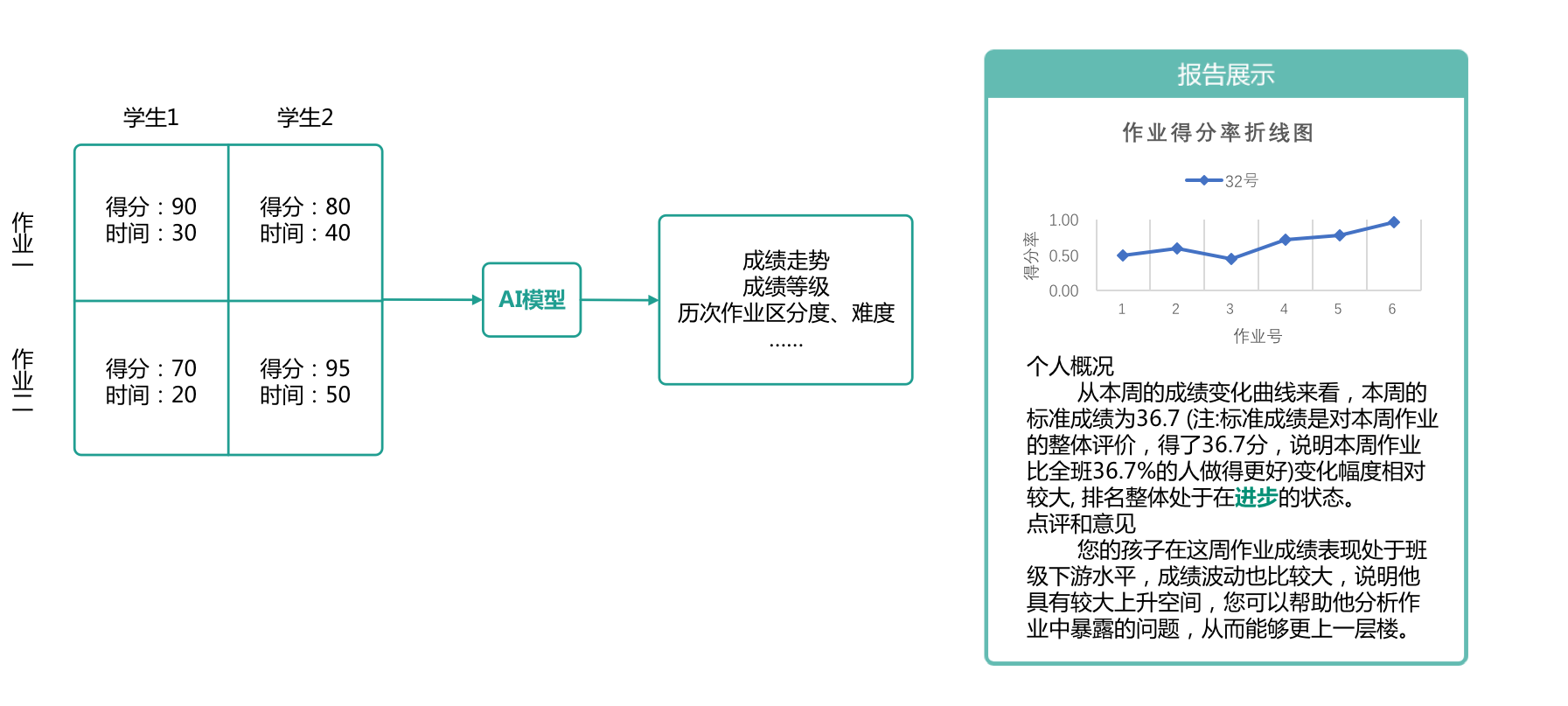 学生建模图示
学生建模图示
其他
实验室还在筹划开设其他和深度学习、智慧教育相关的研究课题。