
FastCNN: Towards Fast and Accurate Spatio-temporal Network for HEVC Compressed Video Enhancement
Zhijie Huang, Jun Sun, Xiaopeng Guo
Abstract:
Deep neural networks have achieved remarkable success in HEVC compressed video quality enhancement. However, most existing multi-frame based methods either deliver unsatisfactory results or consume a significant amount of resources to leverage temporal information of neighbor frames. For the sake of practicality, a thorough investigation of the architecture design of the video quality enhancement network, regarding enhancement performance, model parameters, and running speed, is essential. In this paper, we firstly propose an efficient alignment module that can fast and accurately aggregate the spatio-temporal information of neighbor frames. The proposed module estimates deformable offsets progressively in lower resolution space, motivated by the observation of offset correlations between adjacent pixels. Then the quantization parameter (QP) that represents the compression level prior knowledge is utilized to guide the aligned feature enhancement. By combining alignment feature distillation with residual feature correction, we obtain an efficient QP attention block. To save the storage space of the network, we design a hash buffer to store QP embedding features. The efficient components allow our network to effectively exploit temporal redundancies and obtain favorable enhancement capability while maintaining a lightweight structure and fast running speed. Extensive experiments demonstrate that the proposed approach outperforms state-of-the-art methods over different QPs by up to 0.09-0.11dB, while the inference time can be reduced by up to 69%.简介:
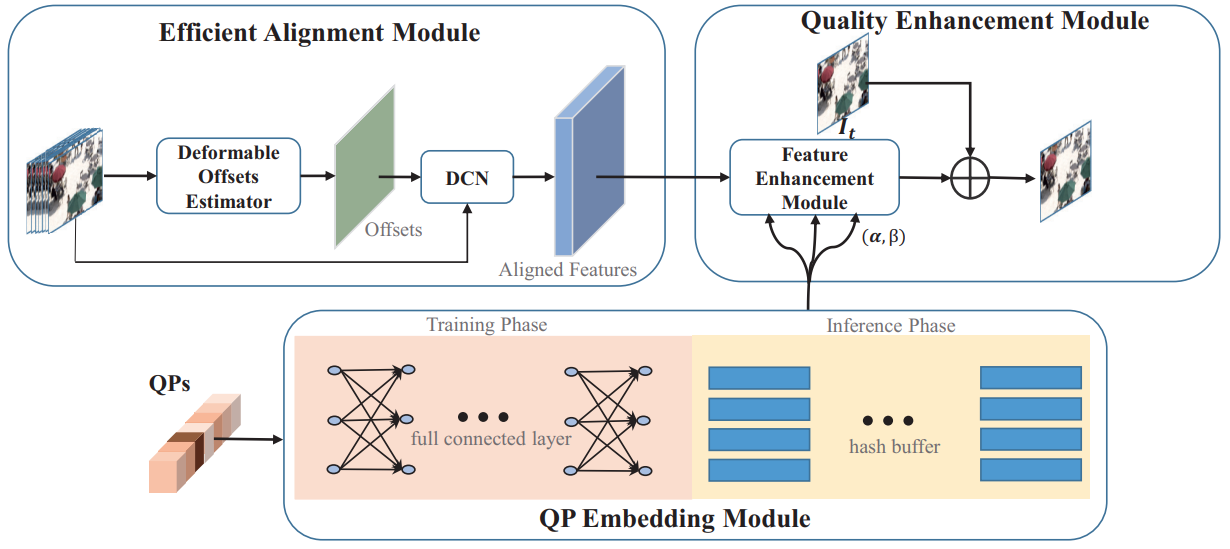
当前,主流的视频编解码标准H.264/AVC,H.265/HEVC,H.266/VVC都采用了基于块的混合压缩编码框架。因此,压缩后的视频通常会出现一些复杂的失真,如块效应、振铃现象、模糊等。这些视觉失真严重降低了观众的体验质量。压缩视频质量增强的目的是从退化的视频中恢复更接近原始帧的清晰帧。这项任务已经成为多媒体和计算机视觉任务中一个越来越重要的研究课题。 目前,深度神经网络在HEVC压缩视频质量提升方面已经取得了显著的成功。然而,现有的大多数基于多帧的增强方法要么效果不甚理想,要么需要消耗大量的资源来利用相邻帧的时域信息。现有方法的性能远远不能达到实时性,而一种快速的、不牺牲质量的方法对于实际应用是至关重要的。另一方面,现有的工作忽略了量化参数对压缩视频增强的影响。由于不同的量化参数,不同帧的质量存在相对明显的变化。因此,值得研究的是如何有效地利用多帧量化参数信息用于视频增强。 为了解决上述问题,我们首先提出了一个基于可变形卷积的高效压缩视频增强方法框架,如图1所示。该框架由时域对齐模块、量化参数嵌入模块以及特征增强模块构成。其中,我们观察到相邻像素之间的偏移相关性,从而提出从较低的分辨率空间中逐步估计可变形卷积的偏移量,进而以快速、准确地融合相邻帧的时空信息。然后,代表压缩水平先验知识的量化参数被利用来指导对齐特征的增强。通过将对齐特征微调与残差特征校正相结合,我们得到了一个高效的量化参数注意力块。为了节省网络的存储空间,我们设计了一个哈希缓冲器来存储量化参数的嵌入特征。这些高效的组件使我们的网络能够有效地利用相关信息,同时保持轻量级结构和极快的运行速度。 如图2所示,实验表明所提出的方法与最新方法相比,不仅增强质量更优,同时推理速度也更快。这部分成果发表在2022年的ACM Transactions on Multimedia Computing, Communications, and Applications上。文章已被TOMM2022收录,了解更多。